
Clare Roper, the Director of Science, Technology and Engineering at WHS explores the world of big data. As teachers should we be aware of big data? Why, and what data is being collected on our students every day… but equally relevant questions about how we could increase awareness of the almost unimaginable possibilities that big data might expose our students to in the future.
The term ‘big data’ was first included in the Oxford English Dictionary in 2013 where it was defined as “extremely large data sets that may be analysed computationally to reveal patterns, trends, and associations.”[1] In the same year it was listed by the UK government as one of the eight great technologies that now receives significant investment with the aim of ensuring the country is a world leader in innovation and development.[2]
‘Large data sets’ with approximately 10000 data points in a spreadsheet have recently introduced into the A Level Mathematics curriculum, but ‘big data’ is on a different scale entirely with the amount of data expanding at such speed, that it cannot be stored or analysed using traditional methods. In fact, it is predicted that between 2012 and 2020 the global volume of data will increase exponentially from 4.4 zettabytes to 44 zettabytes (ie. 44 x1021 bytes)[3] and data scientists now talk of ‘data lakes’ and ‘dark data’ (data that you do not know about).
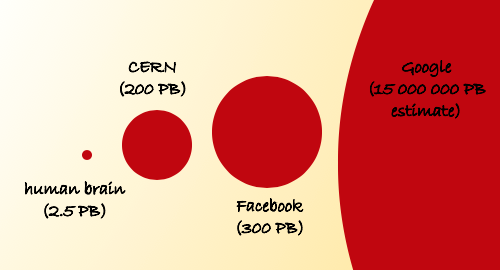
But should we be collecting every piece of data imaginable in the hope it might be useful one day, and is that even sustainable or might we be sinking in these so-called lakes of data? Many data scientists argue that data on its own actually has no value at all and that it is only when it is analysed in context that it becomes valuable. With the introduction of GDPR in the EU, there has been a lot of focus on data protection, data ethics and the ownership and security of personal data.
At a recent talk at the Royal Institute, my attention was drawn to the bias that exists in some big data sets. Even our astute Key Stage 3 scientists will be aware that if the data you collect is biased, then inevitably any conclusions drawn from it will at best be misleading, but more likely, be meaningless. The same premise applies to big data. The example given by Maja Pantic from the Samsung AI Lab in Cambridge, referred to facial recognition, and the cultural and gender bias that currently exist within some of the big data behind the related software – but this is only one of countless examples of bias within the big data on humans. With more than half the world’s population online, digital data on humans makes up the majority of a phenomenal volume of big data that is generated every second. Needless to say, those people who are not online are not included in this big data, and therein lies the bias.
There are many examples in science where the approach to big data collection has been different to that collected on humans (unlike us, chemical molecules do not generate an online footprint by themselves) and new fields in many sciences are advancing because of big data. Weather forecasting and satellite navigation rely on big data and new technologies have emerged including astroinformatics, bioinformatics (boosted even further recently thanks to an ambitious goal to sequence the DNA of all life – Earth Biogenome project ), geoinformatics and pharmogenomics to name just a few. Despite the fact that the term ‘big data’ is too new to be found in any school syllabi as yet, here at WHS we are already dabbling in big data (eg. MELT project, IRIS with Ark Putney Academy, Twinkle Orbyts, UCL with Tolcross Girls’ and Tiffin Girls’ and the Missing Maps project).
To grapple with the idea of the value of big data collections and what we should or should not be storing and analysing, I turned to CERN (European Organisation of Nuclear Research). They generate millions of collisions every second from the Large Hadron Collider and therefore will have carefully considered big data collection. It was thanks to the forward thinking of the British scientist, Tim Berners-Lee at CERN that the world wide web exists as a public entity today and it seems scientists at CERN are also pioneering in their outlook on big data. Rather than store all the information from every one of the 600 million collisions per second (and create a data lake), they discard 99.99% of this data as it is produced and only store data for approximately 100 collisions per second. Their approach is born from the idea that although they might not know what they are looking for, they do know what they have already seen [4]. Although CERN is not using DNA molecules for the long-term storage of their data yet, it seems not so far-fetched that one of a number of new start-up companies may well make this a possibility soon. [5]
None of us know what challenges lie ahead for ourselves as teachers, nor our students as we prepare them for careers we have not even heard of, but it does seem that big data will influence more of what we do and invariably how we do it. Smart data, i.e. filtered big data that is actionable, seems a more attractive prospect as we work out how balance intuition and experience over newer technologies reliant on big data where there is a potential for us to unwittingly drown in the “data lakes” we are now capable of generating. Big data is an exciting, rapidly evolving entity and it is our responsibility to decide how we engage with it.
[1] Oxford Dictionaries: www.oxforddictionaries.com/definition//big-data, 2015.
[2] https://www.gov.uk/government/speeches/eight-great-technologies
[3] The Digital Universe of Opportunities: Rich Data and the Increasing Value of the Internet of Things, 2014, https://www.emc.com/leadership/digital-universe/
[4] https://home.cern/about/computing
[5] https://synbiobeta.com/entering-the-next-frontier-with-dna-data-storage/